Posts
-
MikroTik hEX (RB750Gr3) Review
The MikroTik hEX (RB750Gr3) is a simple wired router - one of the cheapest from the Latvian company - that surely does its job. It’s really flexible, which is simultaneously both a pro and a con. It’s the router with the largest amount of configuration options that I ever seen, including the possibility of making any sort of LAN/WAN combination from the five ports available.
Impressions
- One of MikroTik’s RouterOS biggest features are the countless configuration options in its GUI, both though web and via the native application WinBox. The problem is that a considerable chunk of its documentation, both in the official channels and from random tips scattered around the Internet, is focused on its CLI (called just
Terminal). - It has a non-standard factory reset process. One has to hold its reset button, which is super thin and can’t be reached with a pen, as soon as the device is connected to the power supply. It’s not enough to just hold the reset button anytime.
- Its configuration options are flexible, incredibly flexible, to the point that it doesn’t prevent the user from doing a catastrophic and irreversible change. In the first time I was setting up the LAN bridge options, I somehow removed the port in which the router IP (
192.168.88.1) was associated with. This made it completely lose connectivity and there was no way to access its web UI ever again. Had to reset it to restore access after that. - The wizard configuration system called
Quick Setoffers very few options for people who want to configure the router as quick as possible. And the same time, it does too much magic under the hood, resulting in possible headaches in the future. I don’t recommend using it. - After resetting the device a couple times and configure everything by hand in the
WebFig, its web GUI, I scratched my head to understand how to access this interface after connecting through a Wi-Fi router, which I had to use given it only offers wired connections.- As the Wi-Fi router was giving me an IP in the
192.168.0.0/24range, I wasn’t able to access the router at192.168.88.1, even though the Wi-Fi router could reach it. I was only able to access it after manually adding the192.168.0.0/16range as allowed to theadminuser. When usingQuick Setthis isn’t needed, as this configuration is done without ever informing the user.
- As the Wi-Fi router was giving me an IP in the
- Some options aren’t available in the
WebFiginterface, like changing the MAC address of the ethernet ports directly. At the same time theQuick Setdoes this (maybe via CLI in the background), suggesting that this is indeed possible. A workaround for that is to create a single-port bridge and change the MAC address of this virtual interface. - It’s super easy to update the device, considering both the RouterOS and its firmware itself, which are two separate processes. Given that internet access is properly configured, all that is required are a couple clicks in the interface and a reboot to perform each one of them.
Conclusion
It’s not a router that I would recommend for the faint of heart nor people who are not ready to face a few frustrations. Even I, being someone used to configure routers even before I was 15 years old, scratched my head to understand how a few things work and spent at least 3 hours to leave it as close as possible from what I wanted. Even though, I wasn’t able to configure the Dual-WAN option with a stand-by connection that is automatically activated when the main one goes down. Via the web UI this didn’t work right and via CLI it looked like too much of a hassle.
In the end I was able to manage both connections manually, accessing the
WebFigand deactivating one while re-activating the other. This is still better than physically switching the cable from one modem to the other, and still having to access the configuration page to switch between DHCP and PPPoE in the Wi-Fi router solely WAN port.I’m considering trying out a MikroTik Wi-Fi router, given that having fewer devices involved might simplify the setup. Having one less device connected to the uninterruptible power supply will also probably improve its autonomy.
- One of MikroTik’s RouterOS biggest features are the countless configuration options in its GUI, both though web and via the native application WinBox. The problem is that a considerable chunk of its documentation, both in the official channels and from random tips scattered around the Internet, is focused on its CLI (called just
-
Importing CSV files with SQLite
GitHub offers a very superficial view of how GitHub Actions runners are spending their minutes on private repositories. Currently, the only way to get detailed information about it is via the
Get usage reportbutton in the project/organization billing page. The only problem is that the generated report is a CSV file, shifting the responsibility of filtering and visualizing data to the user. While it’s true that most of the users of this report are used to deal with CSV files, be them developers or accountants experts in handling spreadsheets, this is definitely not the most user-friendly way of offering insights into billing data.When facing this issue, at first I thought about using harelba/q to query the CSV files directly in the command line. The problem is that
qisn’t that straightforward to install, as apparently it is not available viaaptnorpip, nor one is able to easily change the data once it’s imported, like in a regular database. In the first time I resorted to create a database on PostgreSQL and import the CSV file into it, but after that I never remember the CSV import syntax and it still requires a daemon running just for that. I kept thinking that there should be a simpler way: what if I use SQLite for that?In order to not have to
CAST()eachTEXTcolumn whenever working with dates or numbers, the followingschema.sqlcan be used:CREATE TABLE billing ( date DATE, product TEXT, repository TEXT, quantity NUMERIC, unity TEXT, price NUMERIC, workflow TEXT, notes TEXT );After that, it’s possible to import the CSV file with the
sqlite3CLI tool. The--skip 1argument to the.importcommand is needed to avoid importing the CSV header as data, given that SQLite considers it to be a regular row when the table already exists:$ sqlite3 github.db SQLite version 3.36.0 2021-06-18 18:58:49 Enter ".help" for usage hints. sqlite> .read schema.sql sqlite> .mode csv sqlite> .import --skip 1 c2860a05_2021-12-23_01.csv billing sqlite> SELECT COUNT(*) FROM billing; 1834Now it’s easy to dig into the billing data. In order to have a better presentation,
.mode columncan be enabled to both show the column names and align their output. We can, for instance, find out which workflows consumed most minutes in the last week and their respective repositories:sqlite> .mode column sqlite> SELECT date, repository, workflow, quantity FROM billing WHERE date > date('now', '-7 days') AND product = 'actions' ORDER BY quantity DESC LIMIT 5; date repository workflow quantity ---------- ----------------- ------------------------------------ -------- 2021-12-21 contoso/api .github/workflows/main.yml 392 2021-12-18 contoso/terraform .github/workflows/staging-images.yml 361 2021-12-22 contoso/api .github/workflows/main.yml 226 2021-12-21 contoso/api .github/workflows/qa.yml 185 2021-12-20 contoso/api .github/workflows/main.yml 140Another important example of the data that can be fetched is the cost per repository in the last week, summing the cost of all their workflows. An
UPDATEstatement is required to apply a small data fix, given that the CSV contains a dollar sign$in the rows of thepricecolumn that needs to be dropped:sqlite> UPDATE billing SET price = REPLACE(price, '$', ''); sqlite> SELECT repository, SUM(quantity) * price AS amount FROM billing WHERE date > date('now', '-7 days') AND product = 'actions' GROUP BY repository; repository amount ------------------ ------ contoso/api 11.68 contoso/public-web 0.128 contoso/status 1.184 contoso/terraform 2.92 contoso/webapp 0.6Not intuitive as a web page where one can just click around to filter and sort a report, but definitely doable. As a side note, one cool aspect of SQLite is that it doesn’t require a file database do be used. If started as
sqlite3, with no arguments, all of it’s storage needs are handled entirely in memory. This makes it even more interesting for data exploration cases like these, offering all of its queries capabilities without ever persisting data to disk. -
Configuring firewalld on Debian Bullseye
After doing a clean Debian 11 (Bullseye) installation on a new machine, the next step after installing basic CLI tools and disabling SSH root/password logins was to configure its firewall. It’s easy to imagine how big was my surprise when I found out that the
iptablescommand wasn’t available. While it’s known for at least 5 years that this was going to happen, it still took me some time to let the idea of its deprecation sink and actually digest the situation. I scratched my head a bit wondering if the day I would be obliged to learn how to use nftables had finally came.While looking for some guidance on what are the best practices to manage firewall rules these days, I found the article “What to expect in Debian 11 Bullseye for nftables/iptables”, which explains the situation in a straightforward way. The article ends up suggesting that firewalld is supposed to be the default firewall rules wrapper/manager - something that is news to me. I never met the author while actively working on Debian, but I do know he’s the maintainer of multiple firewall-related packages in the distribution and also works on the netfilter project itself. Based on these credentials, I took the advice knowing it came from someone who knows what they are doing.
A fun fact is that the
iptablespackage is actually a dependency forfirewalldon Debian Bullseye. This should not be the case on future releases. After installing it, I went for the simplest goal ever: block all incoming connections while allowing SSH (and preferably Mosh, if possible). Before doing any changes, I tried to familiarize myself with the basic commands. I won’t repeat what multiple other sources say, so I suggest this Digital Ocean article that explains firewalld concepts, like zones and rules persistency.In summary, what one needs to understand is that there are multiple “zones” within firewalld. Each one can have different sets of rules. In order to simplify the setup, I checked what was the default zone, added the network interface adapter to it and defined the needed rules there. No need for further granularity in this use case. Here, the default zone is the one named
public:$ sudo firewall-cmd --get-default-zone public $ sudo firewall-cmd --list-all public target: default icmp-block-inversion: no interfaces: sources: services: dhcpv6-client ssh ports: protocols: forward: no masquerade: no forward-ports: source-ports: icmp-blocks: rich rules:Knowing that, it was quite simple to associate the internet-connected network interface to it and update the list of allowed services.
dhcpv6-clientis going to be removed because this machine isn’t on an IPv6-enabled network:$ sudo firewall-cmd --change-interface eth0 success $ sudo firewall-cmd --add-service mosh success $ sudo firewall-cmd --remove-service dhcpv6-client successIt’s important to execute
sudo firewall-cmd --runtime-to-permanentafter confirming the rules where defined as expected, otherwise they would be lost on service/machine restarts:$ sudo firewall-cmd --list-all public (active) target: default icmp-block-inversion: no interfaces: eth0 sources: services: mosh ssh ports: protocols: forward: no masquerade: no forward-ports: source-ports: icmp-blocks: rich rules: $ sudo firewall-cmd --runtime-to-permanent successA side effect of the
target: defaultsetting is that itREJECTs packets by default, instead ofDROPing them. This basically informs the client that any connections were actively rejected instead of silently dropping the packets - the latter which might be preferable. It’s confusing why it’s calleddefaultinstead ofREJECT, and also not clear if it’s actually possible to change the default behavior. In any case, it’s possible to explicitly change it:$ sudo firewall-cmd --set-target DROP --permanent success $ sudo firewall-cmd --reload successThe
--set-targetoption requires the--permanentflag, but it doesn’t apply the changes instantly, requiring them to be reloaded.An implication of dropping everything is that ICMP packets are blocked as well, preventing the machine from answering
pingrequests. The way this can be configured is a bit confusing, given that the logic is flipped. There’s a need to enableicmp-block-inversionand add (which in practice would be removing it) an ICMP block forecho-request:$ sudo firewall-cmd --add-icmp-block-inversion success $ sudo firewall-cmd --add-icmp-block echo-request successThe result will look like this, always remembering to persist the changes:
$ sudo firewall-cmd --list-all public (active) target: DROP icmp-block-inversion: yes interfaces: eth0 sources: services: mosh ssh ports: protocols: forward: no masquerade: no forward-ports: source-ports: icmp-blocks: echo-request rich rules: $ sudo firewall-cmd --runtime-to-permanent successFor someone who hadn’t used
firewalldbefore, I can say it was OK to use it in this simple use case. There was no need to learn the syntax fornftcommands nor the one fornftablesrules and it worked quite well in the end. The process of unblocking ICMPpingrequests is a bit cumbersome with the flipped logic, and could have been made simpler, but it’s still doable. All-in-all I’m happy with the solution and will look forward how to use it, for instance, in a non-interactive way with Ansible. -
Exporting Prometheus metrics from Go
Exporting Prometheus metrics is quite straightforward, specially from a Go application - it is a Go project after all, as long as you know the basics of the process. The first step is to understand that Prometheus is not just a monitoring system, but also a time series database. So in order to collect metrics with it, there are three components involved: an application exporting its metrics in Prometheus format, a Prometheus scraper that will grab these metrics in pre-defined intervals and a time series database that will store them for later consumption - usually Prometheus itself, but it’s possible to use other storage backends. The focus here is the first component, the metrics export process.
The first step is to decide which type is more suitable for the metric to be exported. The Prometheus documentation gives a nice explanation about the four types (Counter, Gauge, Histogram and Summary) offered. What’s important to understand is that they are basically a metric name (like
job_queue_size), possibly associated with labels (like{type="email"}) that will have a numeric value associated with it (like10). When scraped, these will be associated with the collection time, which makes it possible, for instance, to later plot these values in a graph. Different types of metrics will offer different facilities to collect the data.Next, there’s a need to decide when metrics will be observed. The short answer is “synchronously, at collection time”. The application shouldn’t worry about observing metrics in the background and give the last collected values when scraped. The scrape request itself should trigger the metrics observation - it doesn’t matter if this process isn’t instant. The long answer is that it depends, as when monitoring events, like HTTP requests or jobs processed in a queue, metrics will be observed at event time to be later collected when scraped.
The following example will illustrate how metrics can be observed at event time:
package main import ( "io" "log" "net/http" "github.com/gorilla/mux" "github.com/prometheus/client_golang/prometheus" "github.com/prometheus/client_golang/prometheus/promhttp" ) var httpRequestsTotal = prometheus.NewCounter( prometheus.CounterOpts{ Name: "http_requests_total", Help: "Total number of HTTP requests", ConstLabels: prometheus.Labels{"server": "api"}, }, ) func HealthCheck(w http.ResponseWriter, r *http.Request) { httpRequestsTotal.Inc() w.WriteHeader(http.StatusOK) io.WriteString(w, "OK") } func main() { prometheus.MustRegister(httpRequestsTotal) r := mux.NewRouter() r.HandleFunc("/healthcheck", HealthCheck) r.Handle("/metrics", promhttp.Handler()) addr := ":8080" srv := &http.Server{ Addr: addr, Handler: r, } log.Print("Starting server at ", addr) log.Fatal(srv.ListenAndServe()) }There’s a single Counter metric called
http_requests_total(the “total” suffix is a naming convention) with a constant label{server="api"}. TheHealthCheck()HTTP handler itself will call theInc()method responsible for incrementing this counter, but in a real-life application that would preferable be done in a HTTP middleware. It’s important to not forget to register the metrics variable within theprometheuslibrary itself, otherwise it won’t show up in the collection.Let’s see how they work using the
xhHTTPie Rust clone:$ xh localhost:8080/metrics | grep http_requests_total # HELP http_requests_total Total number of HTTP requests # TYPE http_requests_total counter http_requests_total{server="api"} 0$ xh localhost:8080/healthcheck HTTP/1.1 200 OK content-length: 2 content-type: text/plain; charset=utf-8 date: Sat, 14 Aug 2021 12:26:03 GMT OK$ xh localhost:8080/metrics | grep http_requests_total # HELP http_requests_total Total number of HTTP requests # TYPE http_requests_total counter http_requests_total{server="api"} 1This is cool, but as the metric relies on constant labels, the measurement isn’t that granular. With a small modification we can use dynamic labels to store this counter per route and HTTP method:
diff --git a/main.go b/main.go index 5d6079a..53249b1 100644 --- a/main.go +++ b/main.go @@ -10,16 +10,17 @@ import ( "github.com/prometheus/client_golang/prometheus/promhttp" ) -var httpRequestsTotal = prometheus.NewCounter( +var httpRequestsTotal = prometheus.NewCounterVec( prometheus.CounterOpts{ Name: "http_requests_total", Help: "Total number of HTTP requests", ConstLabels: prometheus.Labels{"server": "api"}, }, + []string{"route", "method"}, ) func HealthCheck(w http.ResponseWriter, r *http.Request) { - httpRequestsTotal.Inc() + httpRequestsTotal.WithLabelValues("/healthcheck", r.Method).Inc() w.WriteHeader(http.StatusOK) io.WriteString(w, "OK") }Again, in a real-life application it’s better to let the route be auto-discovered in runtime instead of hard-coding its value within the handler. The result will look like:
$ xh localhost:8080/metrics | grep http_requests_total # HELP http_requests_total Total number of HTTP requests # TYPE http_requests_total counter http_requests_total{route="/healthcheck",method="GET",server="api"} 1The key here is to understand that the counter vector doesn’t that mean multiple values will be stored in the same metric. What it does is to use different label values to create a multi-dimensional metric, where each label combination is an element of the vector.
-
RAID on the Ubuntu Server Live installer
My first contact with Ubuntu was in 2006, a little after the first Long-Term Support (LTS) version 6.06 (Dapper Drake) was out. Although it still feels like yesterday, 15 years is a heck of a long time. Things were a bit different by then, as the Canonical LTS offer was of about 3 years on desktop and 5 years on server releases - instead of 5 years for both as it stands to this date. They even sent free CDs to anyone in the world, including shipping, from 2005 to 2011 when the initiative was ended. This may look stupid now, but downloading a CD over a 56k dial-up connection (which was still a thing in multiple parts of the world) used to take over a day. Even ADSL connections were not that much faster, as the most common ones were around 256-300 Kbps.
It took me a few more years to use Linux on a desktop, which I did around the end of 2012, although I was using it on my servers at least since 2010 - the year I started to grab cheap VPS offers from LowEndBox. By 2013 I started to work with Herberth Amaral (which is also one of the most competent professionals I know), where Ubuntu was being used on the servers instead of Debian - the latter being Linux distribution I was used to. That didn’t make a huge difference, as both are quite similar when you don’t consider their desktop UI, but I still opted for Debian on my own machines.
This trend continued when I started to contribute to the Debian Project in 2014, where I used a Debian server as my primary development machine. But, except for this server that I still have 7 years later, almost every other server I had or company that I worked on used Ubuntu - except for one employee that used CentOS. So by the end of last year when I realized that this machine wasn’t getting security updates for almost six months since the Debian Stretch support was ended, I started to think why not just install Ubuntu on it. By doing that, I could forget about this machine for 5 more years until the LTS support ended.
To be fair, to say that I use Ubuntu on “almost every other server” is an understatement. Ubuntu is my go-to OS option on almost every kind of computing environment I use - except for my desktop which is a macOS since 2016. Ubuntu is the OS I use when starting a virtual machine with
vagrant up, an EC2 instance on AWS or when I want to try something quick withdocker run(although I use Alpine Linux frequently in this last use case). So opting for it on a server that is going to run for at least a few more years felt like a natural choice to me - at least until I faced their new server installer.To give a bit of context, by being a Debian-based distribution, Ubuntu used the regular Debian Installer for its server distribution until the 18.04 (Bionic Beaver) LTS release, when it introduced the Ubuntu Server Live Installer. It didn’t work for me, as by the time it didn’t support non-standard setups like RAID and encrypted LVM. This wasn’t a big deal, as it was quite easy to find ISOs with the classic installer, so I ignored this issue for a bit. The old setup offered the features I needed and my expectation was that it was a matter of time for the new installer to be mature enough to properly replace the former.
Last year the new Ubuntu 20.04 (Focal Fossa) LTS release came, where the developers considered the installer transition to be complete. The notes mention the features I missed, so I thought that it would be a good idea to try it out. So let’s see how a RAID-0 installation pans out:
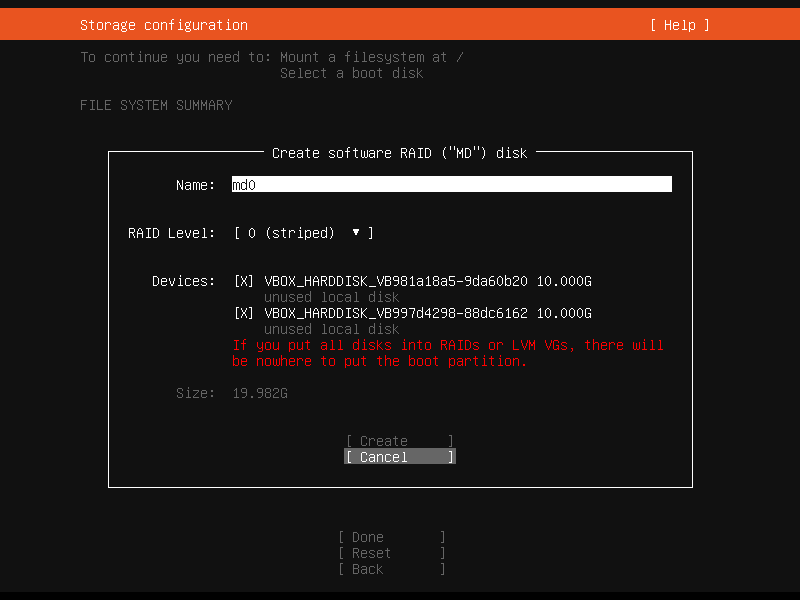
Wait, what?! What do you mean by
If you put all disks into RAIDs or LVM VGs, there will be nowhere to put the boot partition? GRUB supports booting from RAID devices at least since 2008, so I guess it’s reasonable to expect that a Linux distribution installer won’t complain about that 13 years later. To make sure I’m not crazy or being betrayed by my own memory, I tried the same on a Debian Buster installation: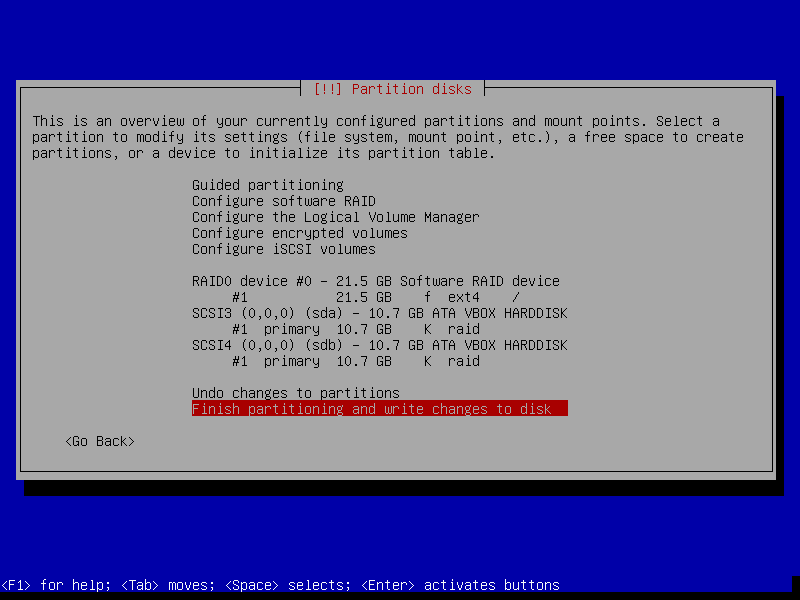
No complaints, no error messages. The installation went all the way and booted fine in the end. “Something is odd”, I thought. By comparing the two partitioning summaries, I noticed that the Debian one is using partitions as a base for the RAID setup, while the Ubuntu one is relying on the entire disks. I went back to the Ubuntu installer and tried to use similar steps. The problem now is that if the option
Add GPT Partitionis used for both devices, it creates two partitions on the first disk and only one on the second disk. So I dropped to a shell from the Live Server installer withALT + F2and manually created empty partitions on both disks withfdisk(cfdiskwill do fine as well). After a reboot, I tried again: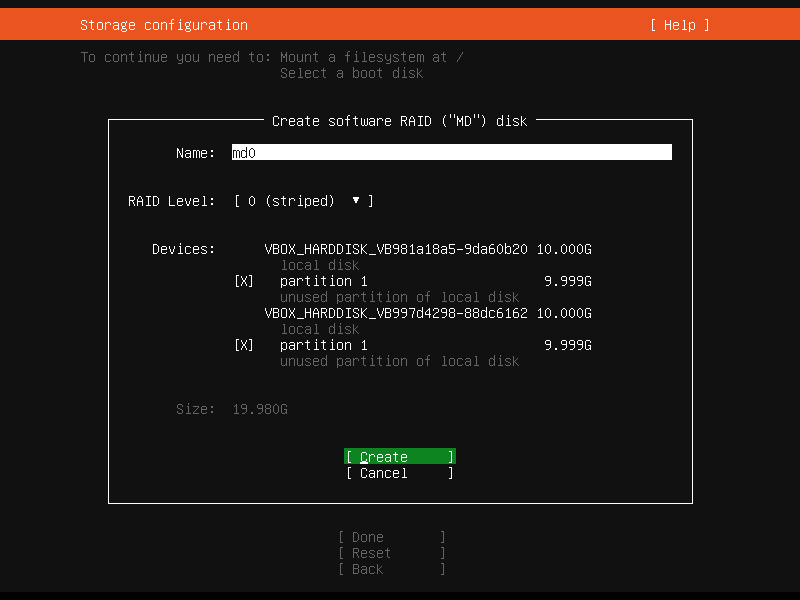
Well, the complaint went away. But after creating the RAID array, opting to format the newly device as
ext4and choosing/for its mount point, theDonebutton was still grayed out. Looking at the top of the screen again, theMount a filesystem at /item was gone, so the last one that needed to be filled was theSelect a boot disk. Clicking on one of the disks and selecting the optionUse As Boot Devicedid the trick.