Posts
-
RAID on the Ubuntu Server Live installer
My first contact with Ubuntu was in 2006, a little after the first Long-Term Support (LTS) version 6.06 (Dapper Drake) was out. Although it still feels like yesterday, 15 years is a heck of a long time. Things were a bit different by then, as the Canonical LTS offer was of about 3 years on desktop and 5 years on server releases - instead of 5 years for both as it stands to this date. They even sent free CDs to anyone in the world, including shipping, from 2005 to 2011 when the initiative was ended. This may look stupid now, but downloading a CD over a 56k dial-up connection (which was still a thing in multiple parts of the world) used to take over a day. Even ADSL connections were not that much faster, as the most common ones were around 256-300 Kbps.
It took me a few more years to use Linux on a desktop, which I did around the end of 2012, although I was using it on my servers at least since 2010 - the year I started to grab cheap VPS offers from LowEndBox. By 2013 I started to work with Herberth Amaral (which is also one of the most competent professionals I know), where Ubuntu was being used on the servers instead of Debian - the latter being Linux distribution I was used to. That didn’t make a huge difference, as both are quite similar when you don’t consider their desktop UI, but I still opted for Debian on my own machines.
This trend continued when I started to contribute to the Debian Project in 2014, where I used a Debian server as my primary development machine. But, except for this server that I still have 7 years later, almost every other server I had or company that I worked on used Ubuntu - except for one employee that used CentOS. So by the end of last year when I realized that this machine wasn’t getting security updates for almost six months since the Debian Stretch support was ended, I started to think why not just install Ubuntu on it. By doing that, I could forget about this machine for 5 more years until the LTS support ended.
To be fair, to say that I use Ubuntu on “almost every other server” is an understatement. Ubuntu is my go-to OS option on almost every kind of computing environment I use - except for my desktop which is a macOS since 2016. Ubuntu is the OS I use when starting a virtual machine with
vagrant up, an EC2 instance on AWS or when I want to try something quick withdocker run(although I use Alpine Linux frequently in this last use case). So opting for it on a server that is going to run for at least a few more years felt like a natural choice to me - at least until I faced their new server installer.To give a bit of context, by being a Debian-based distribution, Ubuntu used the regular Debian Installer for its server distribution until the 18.04 (Bionic Beaver) LTS release, when it introduced the Ubuntu Server Live Installer. It didn’t work for me, as by the time it didn’t support non-standard setups like RAID and encrypted LVM. This wasn’t a big deal, as it was quite easy to find ISOs with the classic installer, so I ignored this issue for a bit. The old setup offered the features I needed and my expectation was that it was a matter of time for the new installer to be mature enough to properly replace the former.
Last year the new Ubuntu 20.04 (Focal Fossa) LTS release came, where the developers considered the installer transition to be complete. The notes mention the features I missed, so I thought that it would be a good idea to try it out. So let’s see how a RAID-0 installation pans out:
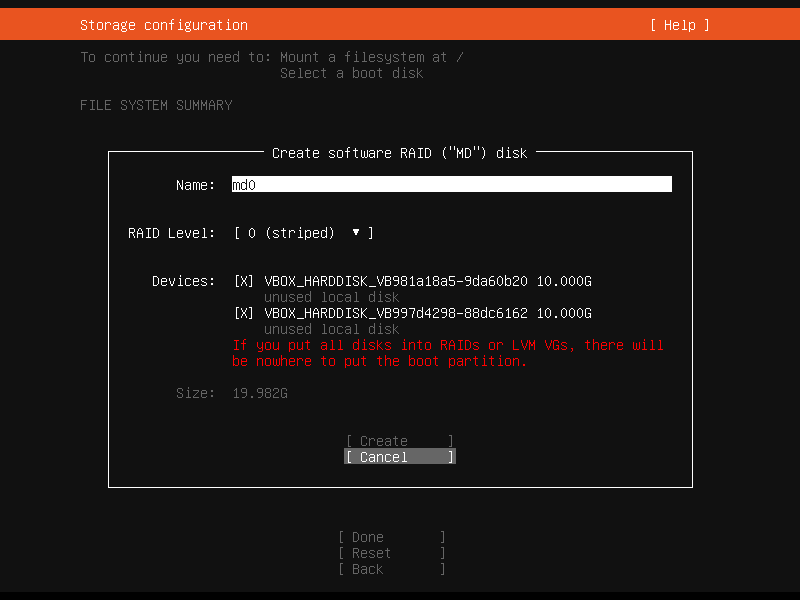
Wait, what?! What do you mean by
If you put all disks into RAIDs or LVM VGs, there will be nowhere to put the boot partition? GRUB supports booting from RAID devices at least since 2008, so I guess it’s reasonable to expect that a Linux distribution installer won’t complain about that 13 years later. To make sure I’m not crazy or being betrayed by my own memory, I tried the same on a Debian Buster installation: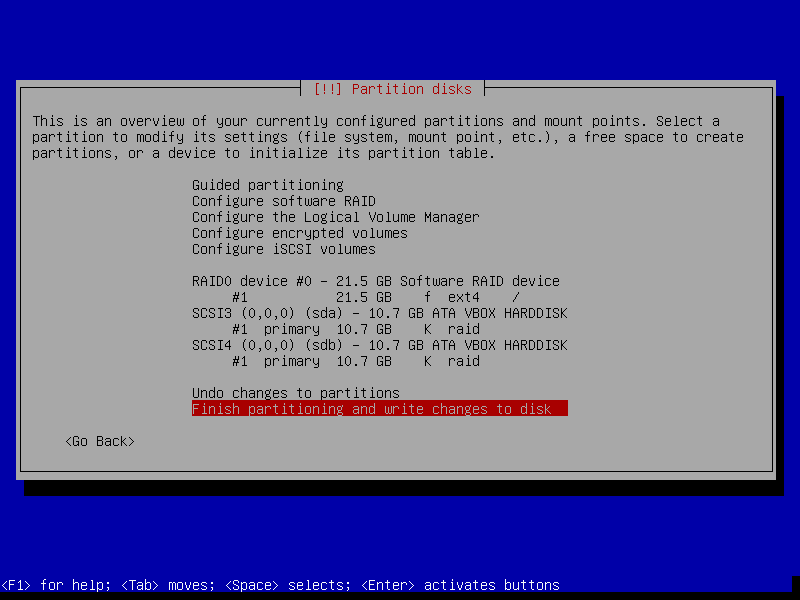
No complaints, no error messages. The installation went all the way and booted fine in the end. “Something is odd”, I thought. By comparing the two partitioning summaries, I noticed that the Debian one is using partitions as a base for the RAID setup, while the Ubuntu one is relying on the entire disks. I went back to the Ubuntu installer and tried to use similar steps. The problem now is that if the option
Add GPT Partitionis used for both devices, it creates two partitions on the first disk and only one on the second disk. So I dropped to a shell from the Live Server installer withALT + F2and manually created empty partitions on both disks withfdisk(cfdiskwill do fine as well). After a reboot, I tried again: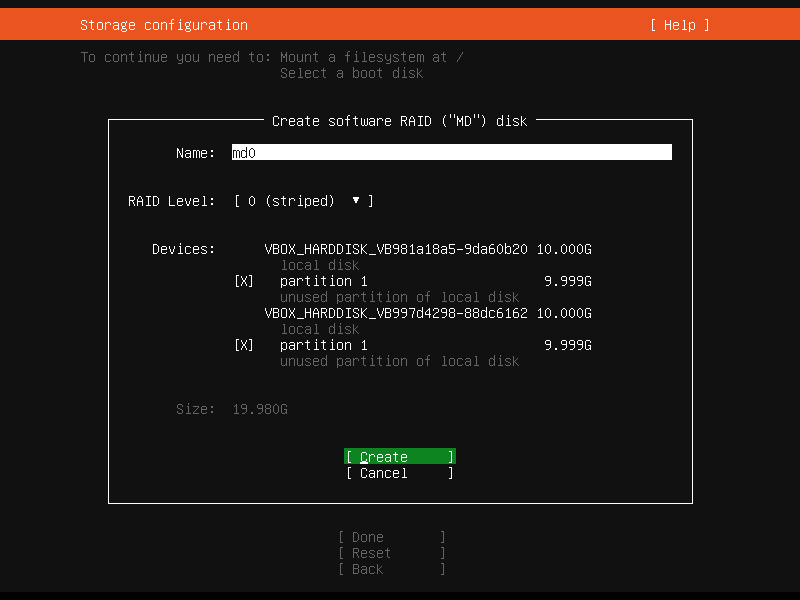
Well, the complaint went away. But after creating the RAID array, opting to format the newly device as
ext4and choosing/for its mount point, theDonebutton was still grayed out. Looking at the top of the screen again, theMount a filesystem at /item was gone, so the last one that needed to be filled was theSelect a boot disk. Clicking on one of the disks and selecting the optionUse As Boot Devicedid the trick. -
Slack threads are one honking great idea -- let's use more of those!
Slack, one of the world’s most popular business communication platforms, launched the threaded conversations feature over 3 years ago. To this day, there are still people who don’t use them, be either for inertia, personal taste, or because they don’t understand its purpose. The goal of this article is to illustrate that by doing the effortless action of clicking the button to Start/View a thread when answering a message, you will be improving not only the life of your future self but doing a huge favor to all your colleagues.
Threaded messages are not just a communication style. They rely on one single pillar to improve the chat tool usability: reduce distractions by giving freedom to their users. Freedom in the sense that they can choose which conversation streams to follow, without having to leave or mute channels - things that may not be wanted or even feasible. And there are many nice side-effects to get in return. Let’s go through some Slack messaging characteristics to better understand their implications.
There’s no need to send multiple separate messages
Which of the following examples is easier to understand:
A bunch of messages sent separately?
Or a single message containing all the needed information:
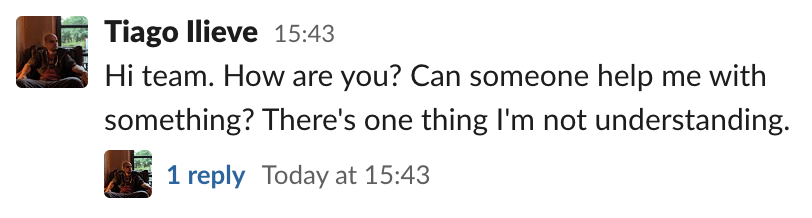
It’s important to notice that the second example directly benefits the usage of threads. The messages that originated it are not scattered around. Also, if you need to append more information, the message may be edited (depending on the Workspace settings). That’s not just aesthetically pleasing, the main issue is that…
Every message sent to a channel is a potential disruption
A channel message may not result in a notification sent to your cellphone or desktop browser, but there are a couple of implications. First, there’s the “unread messages” icon, where the tab favicon turns white. This icon per se can catch someone else’s attention, making them wonder whether their assistance is needed or not. Second, there’s the problem that everybody will have to catch up with all channel messages when they return after being away from the chat. By using threads, the number of channel messages is reduced, making it easier for people to skim through the unread ones, choosing what they need to follow.
Be careful when using the “also send to #channel” option
There’s an option to also send the message to channel when replying to a thread. It should be used with care, for the reasons mentioned above: it will generate a channel message that comes with all its implications. It’s fine to use it, for instance, when sending a reminder to a thread that was started a while ago and needs attention from people that might have not seen it. Selecting this option just to “make a point”, showing what are you are answering to people that might not be interested in the thread may sound condescending and should be avoided.
A thread is a group of related messages
The main goal of using threads - grouping related messages - facilitates a few use cases. A thread can be, for instance, a support request from another team. After the issue is solved, one can tag it with a checkmark emoji indicating that it was concluded.
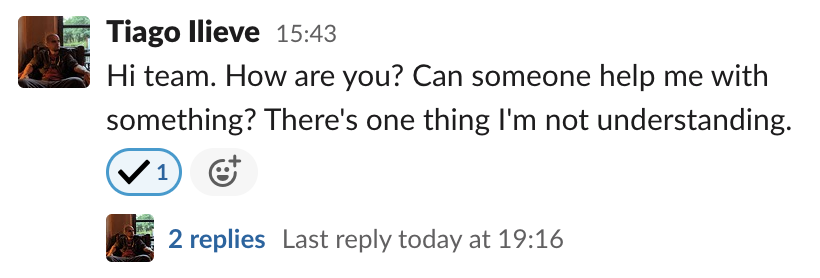
This can either help someone else taking the shift in understanding if any action is needed or an interested third-party to figure if the problem was properly answered/addressed without going through all the messages. Without a thread, it’s hard - impossible in high-traffic channels - to even figure where the conversation ended.
Threads improve message history significantly
Another situation greatly improved by threads is when going through the message history, which is especially useful in the paid - and unlimited - Slack version. Either by using the search or going through a link, when finding the relevant thread all the information is in there: the parent message containing the whole context, all the discussion properly indicating where it started and where it ended. The true value of that can be easily seen, for instance, when a link to discussion is attached to a ticket in the issue tracker and accessed months later.
Closing thoughts
Threads were invented with a noble goal: to make text-based communication more efficient. Even if it might be tempting to take a shortcut and start typing a response when you see a message in a channel, remember that clicking on the Start/View thread button is a small step for you, but a giant leap for whole chatting experience. By doing that the life quality of everyone that might be involved in a Slack conversation, either at that exact point in time or in a long time in the future, will be greatly improved.
-
Formatting a list of strings in Ansible
My Kubernetes Ansible setup - which is, to this date, still the easiest way to bootstrap an on-premises Kubernetes cluster - has a task that installs the packages tied to a specific Kubernetes version. When using it with an Ansible version newer than the one used when it was written, I was bothered by the following deprecation warning:
[DEPRECATION WARNING]: Invoking "apt" only once while using a loop via squash_actions is deprecated. Instead of using a loop to supply multiple items and specifying `name: "{{ item }}={{ kubernetes_version }}-00"`, please use `name: '{{ kubernetes_packages }}'` and remove the loop. This feature will be removed in version 2.11. Deprecation warnings can be disabled by setting deprecation_warnings=False in ansible.cfg.This warning a bit misleading. It’s clear that
item, which comes from thekubernetes_packagesvariable used in awith_itemsoption, is just one part of the equation. The package name is being interpolated with its version, glued together with other characters (=and-00) that will produce something likekubectl=1.17.2-00. Changing it tokubernetes_packagesisn’t enough. The process of replacing this in-place interpolation by a proper list, as Ansible wants, can be achieved in some ways like:- Write down a list that interpolates hard-coded package names with version, like:
kubectl={{ kubernetes_version }}-00. The problem is that this pattern has to be repeated for every package. - Find a way do generate this list dynamically, by applying the interpolation to every item of the
kubernetes_packageslist.
Repetition isn’t always bad, but I prefer to avoid it here. The latter option can be easily achieved in any programming language with functional constructs, like JavaScript, which offers a
map()array method that accepts a function (here, an arrow function) as the argument and returns another array:let pkgs = ['kubelet', 'kubectl', 'kubeadm']; let version = '1.17.2'; pkgs.map(p => `${p}=${version}-00`); (3) ["kubelet=1.17.2-00", "kubectl=1.17.2-00", "kubeadm=1.17.2-00"]Python, the language in which Ansible is written, offers a
map()function which accepts a function (here, a lambda expression) and a list as arguments. The object it returns can then be converted to a list:In [1]: pkgs = ['kubelet', 'kubectl', 'kubeadm'] In [2]: version = '1.17.2' In [3]: list(map(lambda p: '{}={}-00'.format(p, version), pkgs)) Out[3]: ['kubelet=1.17.2-00', 'kubectl=1.17.2-00', 'kubeadm=1.17.2-00']That’s be supposed to be similarly easy in Ansible, given that Jinja, its template language, offers a
format()filter. The problem is that it does not - and will not - support combiningformat()andmap()filters. Another way to do the same would be to use theformat()filter in a list comprehension, but that’s also not supported. But not all hope is lost, as Ansible supports additional regular expression filters, likeregex_replace(). It can be used in many different ways, but here we will use it for doing a single thing: concatenate the package name with a suffix made of another string concatenation operation. This way, the following task:- name: install packages apt: name: "{{ item }}={{ kubernetes_version }}-00" with_items: "{{ kubernetes_packages }}"Is equivalent to:
- name: install packages apt: name: "{{ kubernetes_packages | map('regex_replace', '$', '=' + kubernetes_version + '-00') | list }}"The key is that the
'$'character matches the end of the string, so replacing it is akin to concatenating two strings. Thelistfilter in the end is needed because, just like the equivalent Python built-in function, the Jinjamap()filter also returns a generator. This object then needs to be converted to a list, otherwise, it would result in errors likeNo package matching '<generator object do_map at 0x10bbedba0>' is available, given that its string representation will be used as the package name. - Write down a list that interpolates hard-coded package names with version, like:
-
Web app updates without polling
A co-worker wasn’t happy with the current solution to update a page in our web app, polling some API endpoints every minute. This isn’t just wasteful, as most of the time the requests didn’t bring new data, but also slow, as every change can take up to a minute to propagate. He asked if I knew a better way to do that and while I didn’t have an answer to give right away, I do remember to have heard about solutions for this problem in the past. A quick Stack Overflow search showed three options:
- Long polling: basically what we were already doing.
- WebSockets: persistent connections that can be used to transfer data in both ways.
- Server-Sent Events (SSEs): one-way option to send data from server to client, where the connection is closed after the request is finished.
WebSockets looked like the most interesting option. Their name also reminded me of another technique applications use to push updates to others: Webhooks. That’s how, for instance, a CI/CD job is triggered after changes to a repository are pushed to GitHub. The only problem is that webhooks are, by definition, a server-to-server interaction. A server cannot send an HTTP request to a client. I started to question myself: if so, how do websites like the super cool Webhook.site works?
The
Webhook.siteis a tool meant to debug webhooks. One can set up a webhook, for instance, in GitHub, and inspect the entire body/headers/method of the request in a nice interface, without having to resort to set up a server to do that. The most interesting part is that the requests sent by the webhooks are displayed on the webpage in (near) real-time: exactly the problem I was looking to solve. So I started to look around to figure out how they managed to achieve that.Digging through the page source, I found some references to Socket.IO, which is indeed an engine that was designed to offer bidirectional real-time communication. Before even trying to use it, I tried to understand if it worked over WebSockets and found the following quote on its Wikipedia page:
Socket.IO is not a WebSocket library with fallback options to other realtime protocols. It is a custom realtime transport protocol implementation on top of other realtime protocols.
So,
Socket.IOmay be a nice tool, but not the best alternative for our use-case. There’s no need to use a custom protocol where we might have to, for instance, replace our server implementation when we can opt for a IETF/W3C standard like WebSockets. So I started to think about how webhooks can be integrated with WebSockets.The easiest way would be to store, in-memory, all the currently open WebSocket connections to an endpoint and loop over them every time a webhook request came. The problem is that this architecture doesn’t scale. It’s fine when there’s a single API server, but it wouldn’t work when there are multiple clients connected to different instances of the API server. In the latter case, only a subset of the clients - the ones residing in-memory on the same server which received the webhook - would be notified about this update.
By this point, a previous co-worker and university colleague mentioned that with Redis it would be even simple to achieve that. It didn’t immediately make sense to me, as at first, I thought Redis would only replace the in-memory connections list until I found out about the
PUBLISHcommand. Not only Redis would take care of almost all the logic involved in notifying the connected clients: when combining them with theSUBSCRIBEcommand, it actually offers an entire Pub/Sub solution. It was awesome to learn that the tool I used for over 5 years mainly as a centralized hash table - or queue at max - was the key to simplify the whole architecture.Now it was the time to assemble the planned solution. With Gin + Gorilla WebSocket + Redis in the Backend, together with React in the Frontend, I’ve managed to create Webhooks + WebSockets, a very basic clone of the Webhook.site, showing how real-time server updates can be achieved in a web app by combining the two standards, backed by multiple technologies. The source code is available at GitHub.
-
The Cloud Computing Era is now
I’ve been impressed by how the Cloud Computing landscape changed in the past two years. I totally agree with this quote from Cloudflare:
“And yet, with many serverless offerings today, the first thing they do is the thing that they promised you they wouldn’t — they make you think about servers.”
A solution isn’t serverless if it makes the user think about how much computing resources they need or where these will be located. A truly serverless offer will figure everything that is needed to run a service, in a declarative, not imperative, way. I’ve been amazed by how it’s now easy to combine different services to achieve use cases that simply wouldn’t be possible just a couple of years ago.
One thing that I’ve been doing in the past weeks is to automate some of the manual steps in the tool about water distribution restrictions I wrote. For instance, the page where they post the interruption schedule doesn’t offer an RSS feed. This forced me to bookmark the link and visit it every week, waiting for the new schedule to be published - something that can happen any day between Wednesday and Friday. So I started to wonder: “what if I crawl that page and create an RSS feed for that? This way I can put it in Feedly and be actively informed about new publications”.
Been playing with different HTML parsers recently, like cheerio and goquery - both inspired by the nice, easy-to-use and battle-tested jQuery API, crawling the web page would be the easiest part. The problem is: how was it going to be hosted - and worse, updated frequently? I could set up a cron job in one of my machines, generate the files and publish it with any HTTP server, but that looked like too much of a hassle: one shouldn’t need a server to host and regularly update a static web page in 2020.
I began to think if it would be possible to use the two services that were already in place, Cloudflare Workers Sites and GitHub Actions, the CI/CD solution, to achieve this goal. I mean, of course, the hosting part was already solved, but by the time I didn’t know that it’s possible to schedule events in GitHub Actions, down to 5-minute intervals, in a cron-like syntax:
on: schedule: - cron: '*/5 * * * *'I’m truly astonished by what can we do these days without thinking about servers at all - it’s like IFTTT on steroids. I didn’t have to choose in which region those services are located, nor specify how much CPU/memory/disk/other hardware resources should be allocated to them: I only asked for well-defined tasks, like building the project and deploying it, to be executed on a scheduled basis. And in the GitHub Actions case, there wasn’t even a need to pay for it.
Thinking about how straightforward the whole process have been, I’m inclined to not host anything on a server owned by me ever again.